控制语句
for循环
可用于遍历一维向量(行向量而非列向量)。形如:for 一维向量, 语句1; 语句2; ... end;
>> v = zeros(10, 1);
>> for i=1:10,
> v(i)=2^i; % 缩进只是为了美观
> end;
>> v
v =
v =
1
4
8
16
32
64
128
256
512
1024
2 4 8 16 32 64 128 256 512 1024
>> indices = 1:10;
>> for i=indices,
> disp(i);
> end;
1
2
3
4
5
6
7
8
9
10
while循环
形如: while 条件语句, 语句1; 语句2; ... end;
>> i = 1;
>> while i <= 5,
> v(i) = 100;
> i = i +1;
> end;
>> v
v =
100
100
100
100
100
64
128
256
512
1024
if条件语句
>> v(1) = 2;
>> if v(1)==1,
> disp('The value is one');
> elseif v(1) == 2,
> disp('The value is two');
> else
> disp('The value is not one or two.');
> end;
The value is two
break
>> i=1;
>> while true,
> v(i) = 999;
> i = i+1;
> if i == 6,
> break;
> end;
> end;
>> v
v =
999
999
999
999
999
64
128
256
512
1024
函数
综述
- 函数是一个文件,文件名格式为
函数名.m - 在该函数所在目录下可以直接使用该函数,也可以把该目录添加进搜索路径。
- squareThisNumber.m 的内容:
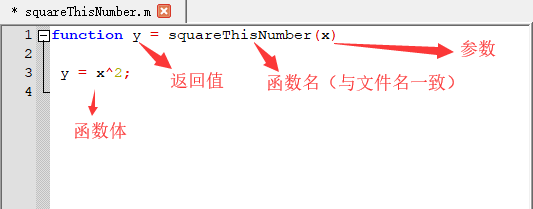
- 直接在目录下执行函数:
>> cd E:\Octave\octave_folder >> squareThisNumber(5) ans = 25 - 或将目录添加到搜索路径中
>> addpath('E:\Octave\octave_folder') >> cd E:\ >> squareThisNumber(5) ans = 25
多个参数和返回值
- squareX1AndCubeX2.m
function [y1, y2] = squareX1AndCubeX2 (x1, x2) y1 = x1^2 y2 = x2^3 - 执行结果
>> [a, b] = squareX1AndCubeX2(2, 3); a = 4 b = 27 >> a = squareX1AndCubeX2(2, 3); % 只返回第一个 a = 4
损失函数(cost function)
- costFunctionJ.m
function J = costFunctionJ (X, y, theta) % X is the "design matrix" containing our training examples. % y is the class labels m = size(X, 1); % numaber of training examples predictions = X*theta; % predictions of hypothesis on all m examples sqrErrors = (predictions-y).^2; %squared errors J = 1 /(2*m) * sum(sqrErrors); -
执行结果
>> X = [1 1; 1 2; 1 3] X = 1 1 1 2 1 3 >> y = [1; 2; 3] y = 1 2 3 >> theta = [0; 1] theta = 0 1 >> j = costFunctionJ(X, y, theta) j = 0