数据获取
获取方式
人工数据合成通常包含两种不同的变体,第一种是创造新的数据集,第二种是扩大数据集。
现代计算机通常都有一个很大的字库。一般文字处理软件中都会有很多的字体存储在字体库中。此外,也有很多可以免费下载字体库的网站。
想获得更多的训练样本,一种方法是采集同一个字符的不同种字体,然后为这些字符加上不同的随机背景。

第二种方法是对图像进行人工扭曲或者人工变形。
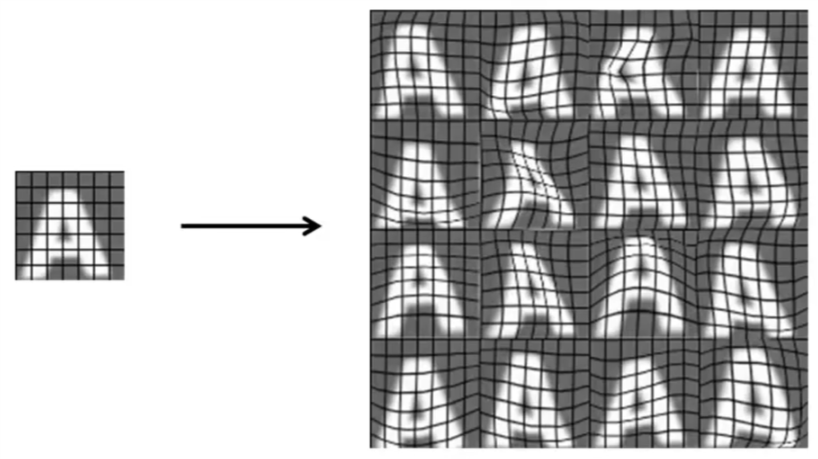
关于获取更多数据的讨论
- 在获取更多数据前确认你有一个低偏差的分类器(画出学习曲线)。例如增加特征/神经网络中的隐含层数目直到得到一个低偏差的分类器。
- 在开发机器学习系统时,你最宝贵的资源就是你的时间。仔细考虑通过各种方式要付出多少工作量才能获得10倍的数据,选择工作量最小的。
- 人工数据合成
- 自己收集/标记数据
- “众包”(crowd source)。例如(Amazon Mechanical Turk)。众包是指通过集合兼职工作和志愿者的零散贡献的途径,以最终实现一个大型工程。
参考资料: