照片OCR
照片OCR的英文全称是:(Photo Optical Character Recognition)。
基本流程
- 文本检测。找出有文本的位置,分离出有文本部分的图像。
- 字符切割。将有上一步骤得到的文本块切割获得一个个单个字符的图像。
- 字符分类。为每个字符图像确定分类,确定到底是哪个字符。
- (拼写检查)。有些字符很容易被混淆,我们可以通过拼写检查来判断是否正确。比如:clean可能被识别为c1ean,此时我们可以通过拼写检查来修正。

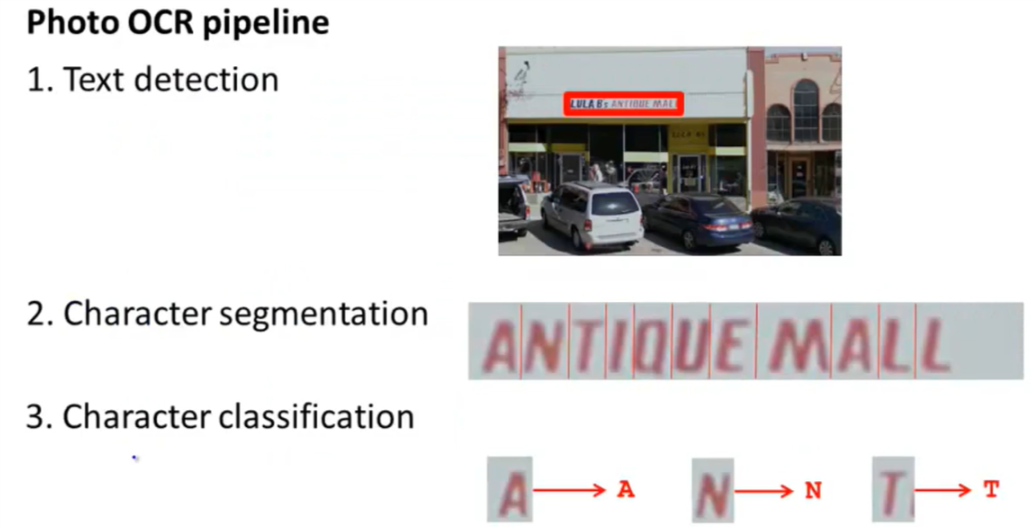
文本检测
我们滑动窗(sliding windows)分类器来进行文本检测。
- 设置滑动窗,确定窗口大小。比如80*40像素。
- 设置步长,设置窗口每次向右或向下移动的距离。
- 滑动窗口。对每次窗口移动获得的图像按有无字符进行分类。
- 对窗口进行放缩,重复3步。
- 对有字符的图像,判断其周围一定距离内是否存在其他字符。若有则将他们连接起来。


字符切割
我们同样使用滑动窗分类器来进行字符切割。
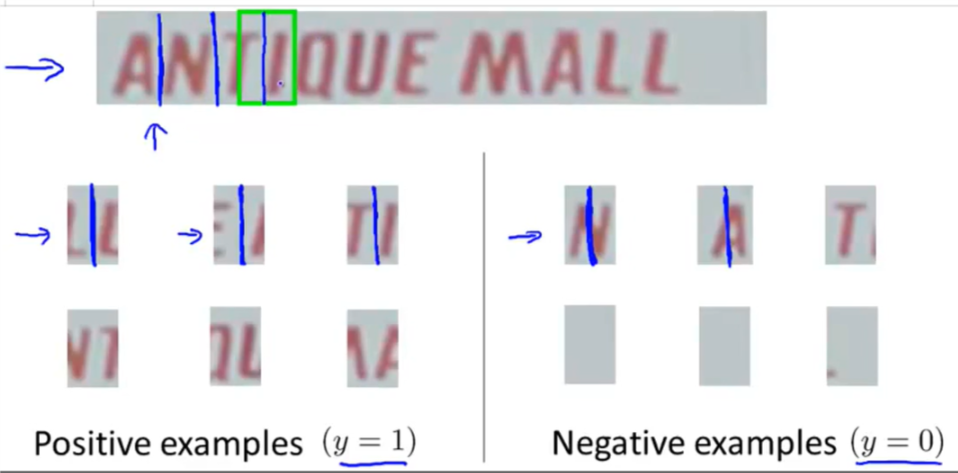
字符分类
利用学过的分类算法进行分类
上限分析(ceiling analysis)
在开发机器学习系统的流水线时,上限分析可以告诉我们改进各个模块对整个系统产生的影响,告诉你最值得把时间花费在流水线中的哪个部分。
以照片OCR流水线为例,首先我们要令文本检测部分的精度为100%,人为的告诉算法每一个样本的出现文字的区域,然后测试系统整体精度。然后我们令字符分割部分的精度为100%,即人为的将原本文本检测得到的输出进行字符分割,测试系统整体精度。最后令字符识别部分的精度为100%,判断系统整体精度。
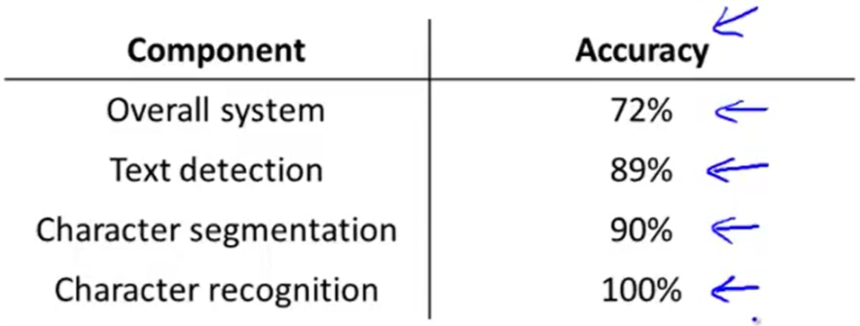
我们可以发现当字符识别部分的精度为100%时,系统的整体精度提升到了100%,优化它会是我们的系统产生更大的进步,故我们应该对它进行优化。
参考资料: